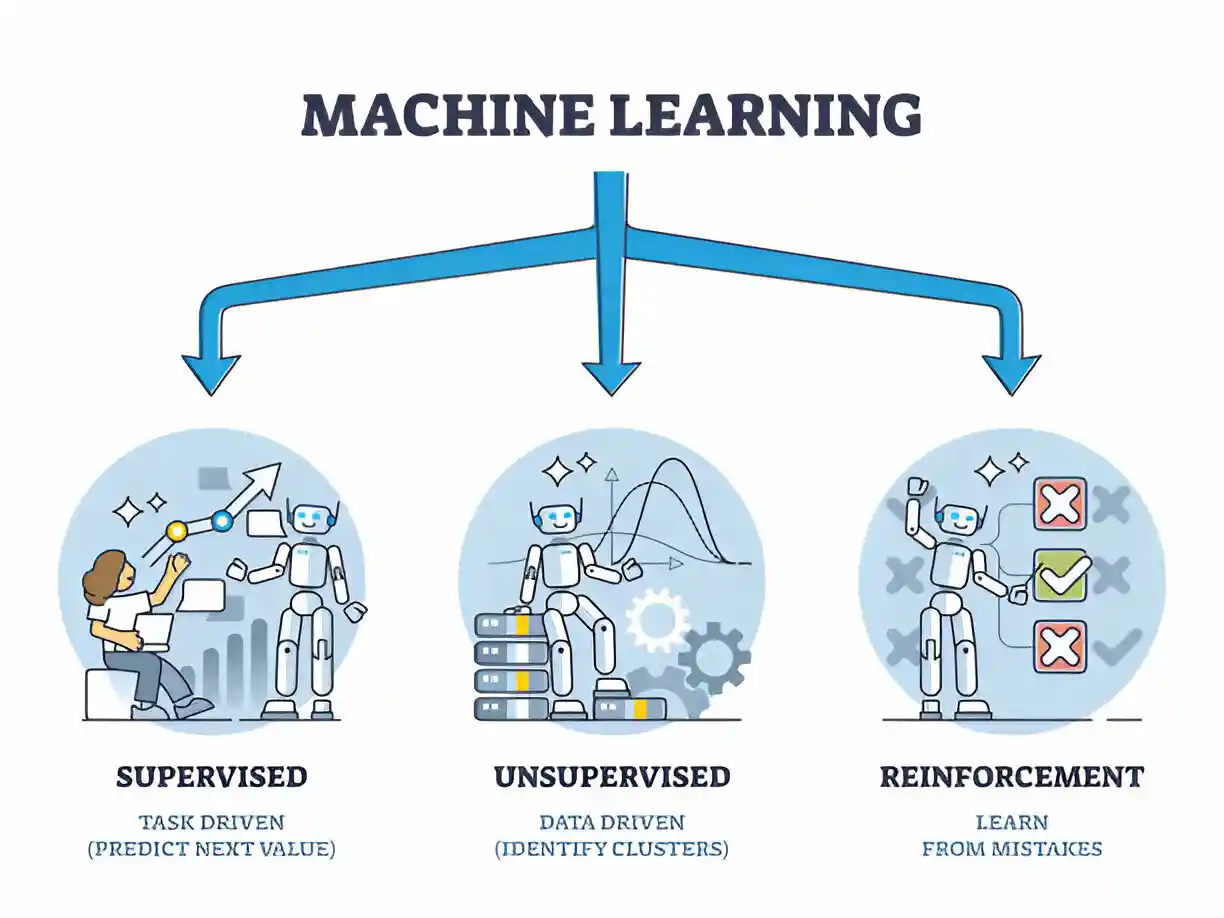
Machine learning has two fundamental approaches that is Supervised and unsupervised learning
Supervised Learning:
In supervised learning, the algorithm learns from labeled data, meaning each input data point is associated with a corresponding target label. The aim is to learn a mapping from input variables to output variables. The algorithm learns to predict the output values from the input data. Supervised learning is typically used in tasks where the goal is to predict future outcomes or classify data into predefined categories. Common algorithms include linear regression, logistic regression, decision trees, support vector machines (SVM), and neural networks.
Unsupervised Learning:
In unsupervised learning, the algorithm learns from unlabeled data, meaning there are no predefined labels associated with the input data. Unsupervised learning is used in several tasks such as clustering, dimensionality reduction, and density estimation. Common algorithms contains k-means clustering, hierarchical clustering, principal component analysis (PCA), and autoencoders.
Here’s a simple analogy:
Supervised learning is like having a teacher who provides you with labeled examples (e.g., this is a cat, this is a dog) and guides you to learn the relationship between features and labels.
Unsupervised learning is like exploring a dataset without any labels. You’re trying to uncover any inherent structure or patterns on your own, without explicit guidance.
In real-world scenarios, both supervised and unsupervised learning techniques are used depending on the nature of the problem and the availability of labeled data. Sometimes, a combination of both approaches, known as semi-supervised learning, is also employed.